みなさんこんにちは、このブログを書いている東急三崎口です。
この記事では、生成AI向けのGPUに必要とされるHBMについて解説します。
HBMについては、生成AI向けの需要が高まっていることはさかんに報道されていますが、詳しい内容について書かれた日本語メディアが少ないと感じたので自分で記事を書くことにしました。
読者の方の中には、仕事でHBMに携わっておられる方もいらっしゃると思いますので、内容の間違い等がありましたら、ご指摘いただけると幸いです。
DRAMについてかんたんに見てみよう
HBMが生成AI向けに需要が高まっていることはよく報道されていますが、実際にどのように使われているのか解説している記事は比較的少ないです。
HBMについて考えるためには、DRAMについて理解する必要があります。DRAMは半導体メモリの一種で、PC・スマホの中には必ずと言っていいほど入っています。
特徴
DRAMの特徴は、電源が切れてしまうとデータを保持できなくなる揮発性メモリであることです。また、速度はNANDフラッシュメモリより速いため、CPUとのデータのやりとりのために使われています。
基本的なセル構造は、1T1Cと呼ばれていて、1つのトランジスタと1つのキャパシタが1セットです。図にすると、このようになります。
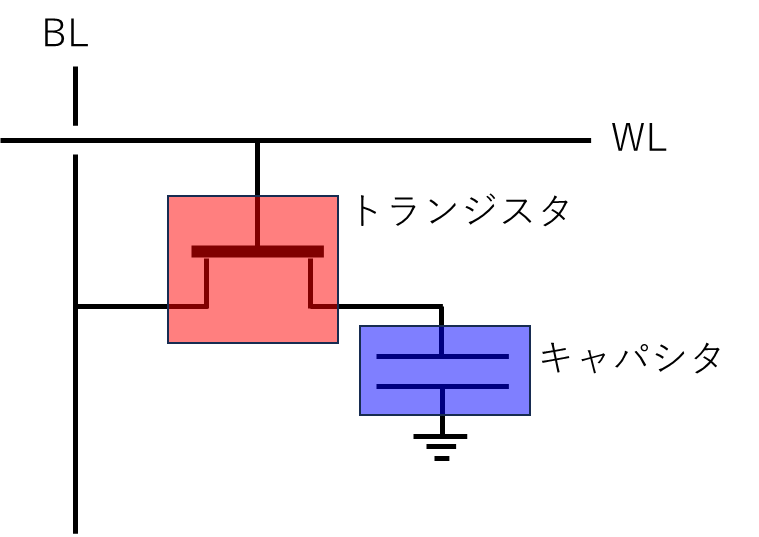
ワードライン(WL)でオンオフを制御するトランジスタを介して、ビットライン(BL)とキャパシタがつながっています。
キャパシタに電荷がたまっていれば1を、電荷が無ければ0を保持していると扱われます。このように、キャパシタの電荷によって、0と1のデータを保持することができます。
NANDフラッシュメモリと違うのは、キャパシタがトランジスタを介して電気的につながっているので、時間が経過すると電荷が少しずつ漏れ出してそのうち0になってしまいます。
元々、1が書き込まれていたキャパシタも時間が経過してしまうと0になってしまいます。そうすると、元々書き込まれていたデータが0か1かわからなくなってしまうので、DRAMは一定時間間隔でリフレッシュ動作というものが行われます。
リフレッシュ動作は、1つ1つのセルに書き込まれていたデータが0なのか1なのかを読み取り、1の場合は電荷を再度書き込む動作です。
DRAMの動作は、書き込み・読み出し・リフレッシュの3つが主です。読み出し・書き込みは、メモリでは一般的に行われますが、リフレッシュ動作があるのがDRAMの特徴です。
基本構造としては、1つのセルは、トランジスタとキャパシタが1つずつついているだけです。
WLとBLを制御するためのトランジスタや、外部へのデータ転送のためのI/O回路はありますが、基本構造は非常にシンプルです。HBMだろうが、普通のDRAMだろうが、基本構造は変わりません。
種類
DRAMにはいくつかの種類があります。名前で分けると4つあります。
・DDR〇
・LPDDR〇
・GDDR〇
・HBM〇
〇の部分には、数字(HBMの場合は数字+Eの場合もあります)が入ります。
もともとはDDR〇しか無かったものが、派生してLPDDR〇、GDDR〇、HBM〇となっています。
DDR〇シリーズは、スタンダードなDRAMで、Double Data Rateの略がDDRです。かつては、SDR(Single Data Rate)DRAMもありましたが、現代ではDDRが一般的なのでDDRだけ知っていれば十分だと思います。
LPDDR〇シリーズは、DDRから消費電力を下げる方向に進化したシリーズです。消費電力を下げる要求は、モバイル機器に搭載されることが増えたことから生まれたと考えられています。
常に電源につながっているデスクトップのPCであれば、それほど消費電力を気にする必要はありませんが、ノートPCやスマートフォンでは消費電力の低減は非常に重要な問題になります。
DDRシリーズとLPDDRシリーズでは、内部に使われている電源電圧が違うので互換性はありません。
GDDR〇シリーズは、GPU向けのDRAMとして作られました。GPUについてはのちほど書きますが、もともとはグラフィック用の専用チップという扱いでした。(あくまで、昔の話です。今では汎用用途に使われるようになっています。)
GDDRシリーズは、GPUとセットで使われるため、転送速度が速くなっています。一方で、転送速度を上げるため、GPUとGDDRメモリの距離や配置に制限が掛かります。
GDDRシリーズは、GPUで使うことを前提に速度と帯域を大きくしていますが、結果として配置や距離に制限が掛かるような設計になっています。
PS5の分解レポートでも、GPUの周りに8つのGDDR6が等距離に置かれています。(PS5の分解レポートは下記リンク先から読めます。)
https://www.4gamer.net/games/990/G999027/20201116053
このようにGDDR〇シリーズはGPUとセットで使う前提で作られていて、性能は高いですが設計に制約が出ます。
最後に、HBM〇シリーズです。HBMは、GPUとセットで使うことはGDDR〇シリーズと一緒ですが、接続するピン数を増やすことで帯域を大きくしようとしています。(帯域に関しては後ほど書きます。)
HBMの特徴として、ピン数が非常に多いことが挙げられます。HBM3だと、1024本のピンがあるようです。
HBMは接続するピン数が非常に多いので、他のDRAMと接続方法が変わってきます。ピンの数が増えて、高密度に接続する必要があるので、従来の方法では全てのピンを接続することができません。
そこで、インターポーザ―を使った接続や、TSVを使ってDRAMダイを積層する方法が取られています。(この辺は後ほど取り上げます。)
つらつらと、DRAMの種類ごとの特徴を書きました。今回着目しているHBMは、GPUとの接続を前提にしているメモリであり、GDDR〇シリーズのハイエンド版と言える立ち位置になっています。
HBMの構造に入る前に、GPUについて簡単に触れます。
GPUとはなんぞや?
生成AI向けに高性能なGPUが飛ぶように売れていることは、よく報道されています。では、GPUは一体何をしているのでしょうか。
GPUは、Graphics Processing Unitの略で、もともとはグラフィック専用の用途のために作られていたものでした。
3DCGをリアルタイムで処理しないといけないようなゲーム向けに、ハイエンドなGPU(グラフィックボード)を買う場合はあったと思います。(あくまでも昔の話です。)
ただ、動画編集とかハイエンドなゲーム向けでなければ、現代ではCPUとGPUが組み込まれている場合が多いので、内臓GPUで事足りてしまうことが多いと思います。
私自身、ハイエンドなGPUを使わなければならない状況になったことがなかったので、GPUについてそれほど詳しく見ていたわけではありませんでした。
ハイエンドなGPUは、画像処理のような単純計算を並列で繰り返すことが得意だとされています。単純計算の例でいえば、行列演算なんかも入ります。
もともとは、グラフィック向けに使われていたGPUですが、汎用計算に使えるようにということで、GPGPU(General-purpose computing on graphics processing units)としての用途にも使われるようになりました。
GPUがハイエンドになればなるほど、メモリの帯域が重要になります。帯域はのちほど書きますが、簡単に書くと(1ピンあたりの転送速度)×(ピンの数)=(帯域)として考えられます。
この帯域を広く取るために、ハイエンドGPUではDRAMの中でもHBMが使われるようになり、生成AI向けにハイエンドGPUの需要が増えたため、HBMの需要も増えているということです。
生成AIにマッチする理由
GPUが生成AIに使われる理由を簡単に見ていきます。
生成AIと一言でいっても、多くの種類がありますが、今回はLLM(Large Language Models)を取り上げます。
LLMの簡単な仕組み
LLMにもいくつかの種類がありますが、有名なのはOpen AIのGPTでしょう。LLMの比較には、パラメータ数が出てきますが、最新版のGPT-4では1兆個のパラメータが使われていると言われています。
このパラメータが、LLMを考えるうえで非常に重要なキーになります。
そもそも、生成AIはどのようにして私たちの入力に対して返答を出力しているのでしょうか。
生成AIを私たちが使う場合の流れは、簡単に書くとこのようになっています。

私たちが入力する内容を入力変数として考えると、生成AIという関数を介して何らかの出力が出てくると捉えることができます。
何らかの入力変数を入れると、それらしい出力が出てきますが、生成AIの中でどんな処理が行われているのかは、利用者である私たちにはわかりません。どんな処理が行われているのかわからないため、中身がブラックボックスな関数という書き方をしています。
生成AIのアルゴリズムは公開されていないので、中身がどうなっているかを知ることはできませんが、大まかな仕組みとしては言葉に対して重みづけのパラメータを置くことで、次にくる言葉を確率的に予測して出力を作っていると言われています。
たとえ話をしてみましょう。こんな文があり、()内の空白を埋める言葉を3択の中から選んでくださいという問いが出されたとすると、どれが答えになるでしょうか。
問題文:金曜日の夜は、居酒屋で( )が飲みたい。
選択肢:ビール・味噌汁・たばこ
ほぼ100%の方は、ビールを選ぶと思います。なぜビールを解答として選べるかを考えてみると、「居酒屋」で「飲みたい」ものを考えると、ビールが一番適切だからでしょう。
つまり、居酒屋で飲みたいという文脈にマッチする言葉を選ぼうとした時に、3択の中ではビールが一番確率が高いわけです。
この例は簡単なものですが、前後の文脈に対して、使われる確率が高い言葉を選ぶことで、生成AIは出力を行っていると考えられます。
前後の文脈に対して使われる確率が高いかどうかは、無数にある言葉同士の関連性と、全体の文脈に対してマッチするかという2つの要素があります。
無数にある言葉同士の関連性については、居酒屋でビールが飲みたいの例文で考えた通りです。ビール以外にも、ウイスキーとかハイボールとかも、関連性が高い言葉だと考えられます。
全体の文脈にマッチするのかというのは、例文の前半部分である「金曜日の夜」という部分に関わってきます。
後に続く文が、「居酒屋でビールを飲みたい」であれば、金曜日の夜で問題ありません。しかし、「居酒屋でビールを飲みたい」の前の部分が、月曜日の朝だったらどうでしょうか。
「月曜日の朝」と「居酒屋でビールを飲みたい」というのは、ゼロでは無いですが、使われる確率が低い組み合わせになります。
このように、個別の言葉の前後の関連性はあっていたとして、全体の文脈に即さない表現は、違和感を感じてしまうわけです。
この辺の処理を実際のLLMはどうしているのかというと、各言葉に対して他の言葉との関連性を示すパラメータを設定することで、使われる確率が高いものを選んで出力しているようです。
言語の中で使われる言葉の数は膨大なので、パラメータ数は多ければ多いほど正確な表現に近づくと考えられます。
パラメータの中の他の言葉に対する重みづけを学習するために、インターネット上のテキストデータが利用されており、膨大なデータを学習することでLLMの学習データを作っていると考えられます。
ここまでが、LLMの簡単な仕組みです。
実際の例
では、中身がわからないブラックボックスな関数と書いた生成AIが、ある入力関数を入れた時にどのように出力されるのかを実際に見てみましょう。
例として、東急三崎口を使ってみます。この言葉は完全な造語(つまり、実在する場所の名前ではないということです)なので、生成AIからすると、どんな出力をするか興味深いです。
今回は、Microsoftが提供しているCopilotとGoogleが提供しているGeminiを使って比較してみます。
Copilotに東急三崎口と入力するとこんな回答が出てきました。
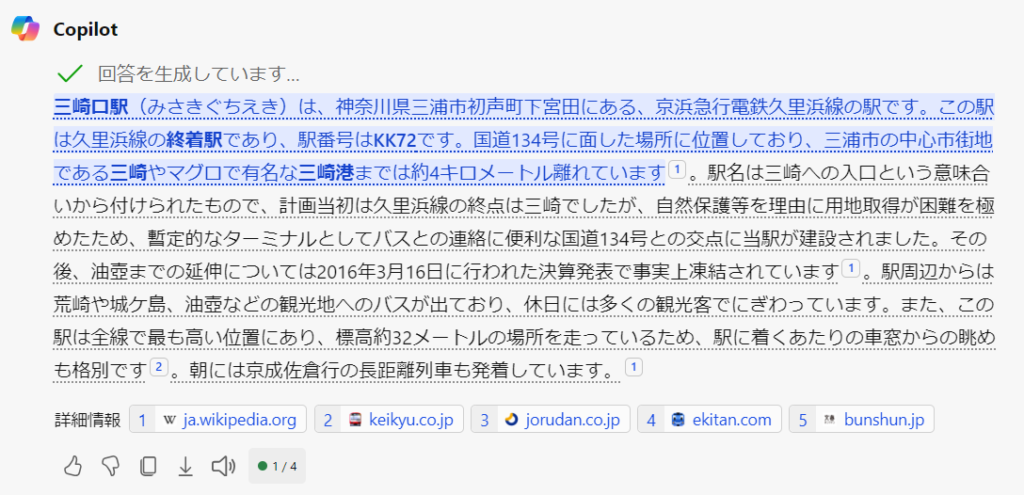
これは、完全に京急の三崎口駅について書かれた回答ですね。おそらく、三崎口について調べた結果を出力しているので、こういった回答になっているのでしょう。
次に、Geminiの解答を見てみます。

こちらも、京急の三崎口駅に関して書かれています。
だいたい、東急三崎口という造語で調べると、こんな感じの答えが出てきます。
次に、「東急三崎口 半導体」で調べてみるとこのようになりました。
Copilot
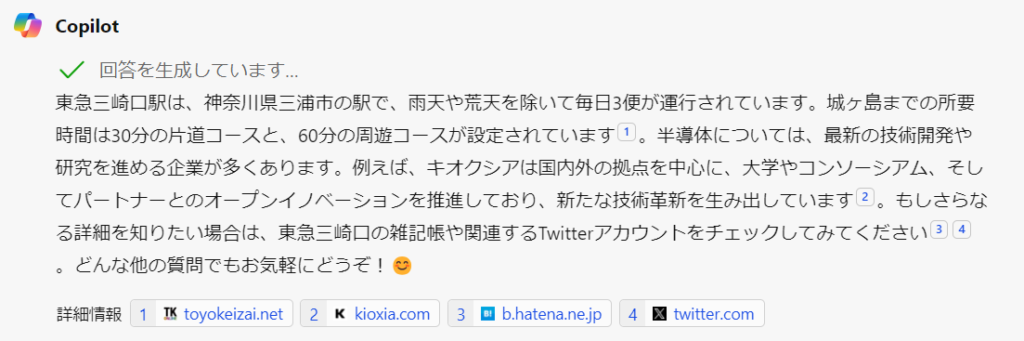
Gemini



CopilotもGeminiも、よくわからん回答が返ってきます。
こういう造語だと、東急/三崎口という風に言葉を切って、三崎口に関することが多く出てくるので、三崎口の紹介をしているのだと考えられます。
また、東急三崎口と半導体は関連の薄い言葉なので、無理矢理くっつけたような回答も出てきます。
生成AIがこういう回答を出してくるのは、相互の言葉の関連性および重みづけを行っていることがよくわかる例ではないかと思い紹介しました。
生成AIの出力は、時間が経つと変わっていることもあるので、興味があったら色々入れてみてください。(ちなみに、情ポヨと入れると、Geminiではそれっぽい答えが返ってきましたよ。)
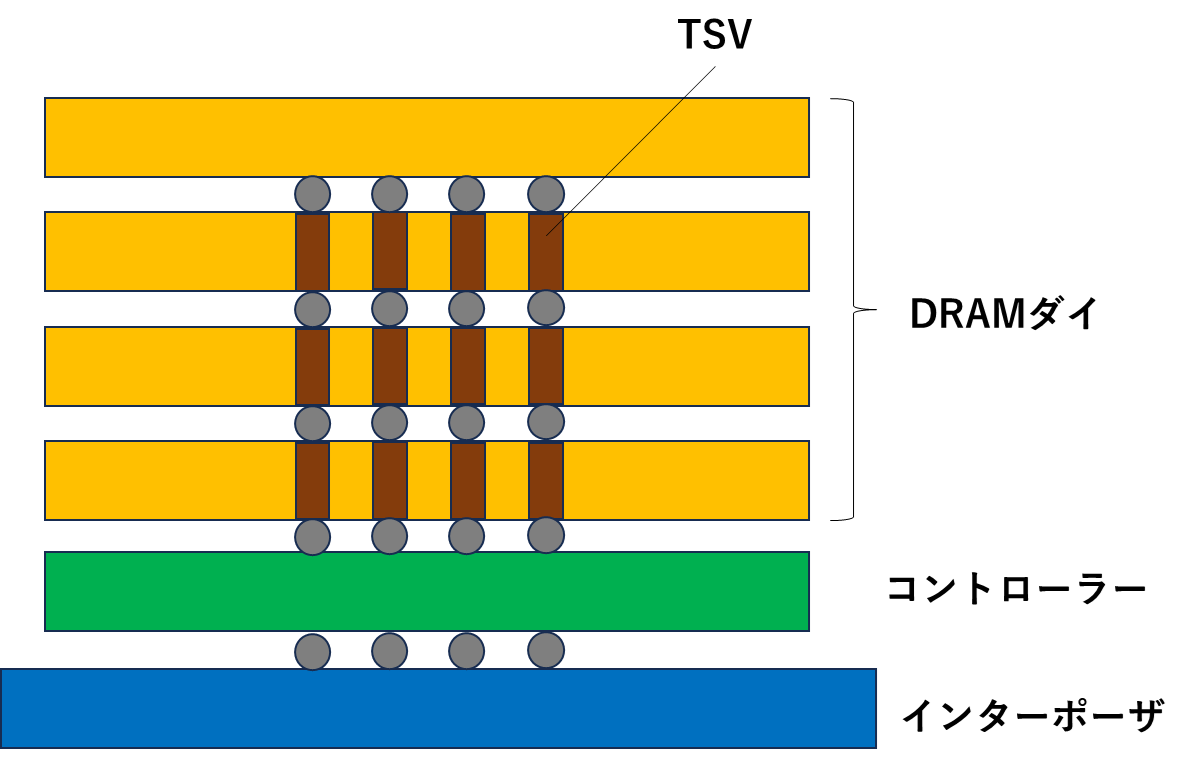
HBMの大まかな構造
さて、ここからが本題ですが生成AIに使われているHBMの大まかな構造を見ていきます。
HBMの構造を考えるときのキーは、インターポーザ・TSV・積層構造です。
HBMが載ったGPUの断面をおおまかに描くとこんな形をしています。
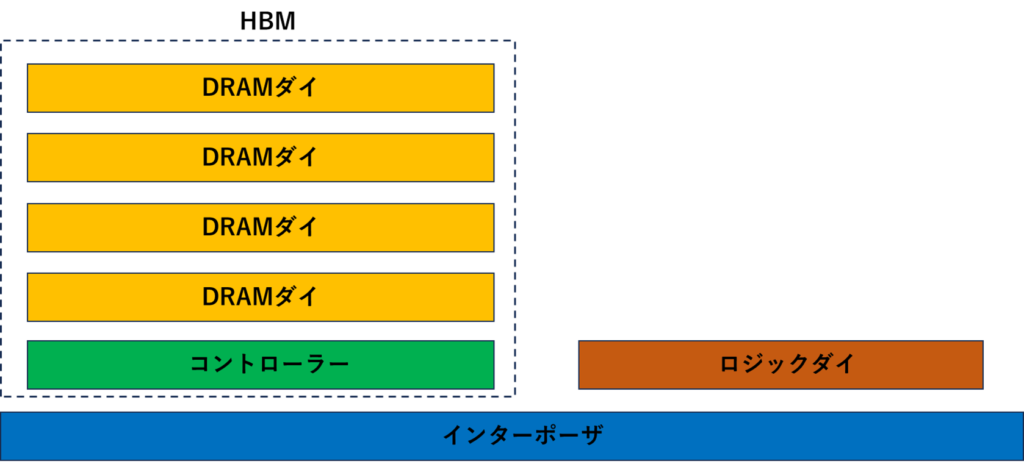
わかりやすさのために、ざっくり描いていますが、ロジックダイ(GPU)とHBMがインターポーザを介してつながっている形になっています。
インターポーザは、微細配線をつなぐことができるので、ロジックダイとHBMの間の接続に使われています。
インターポーザ上に載ったHBM内部の構造を見てみます。
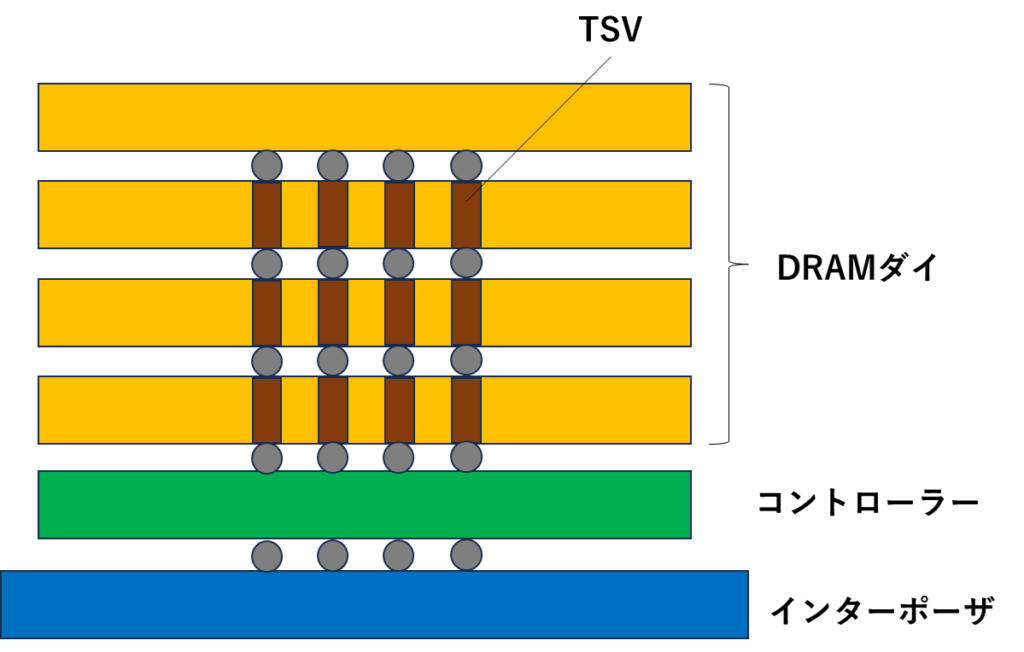
HBMは、DRAMダイを積層した構造になっており、各レイヤはTSV(Throgh Silicon Via)と呼ばれる配線が貫通しています。
TSVは、シリコン基板を貫通する構造になっており、上にあるダイとの配線を担っています。一般的には、Si基板をDeep RIEでエッチングしてCuを埋め込むことで形成されます。各ダイに形成したTSV間はマイクロバンプで接合されます。
これだけと言えば、これだけなんですが、DRAMのダイを積層している点と、高密度に配線が走っているのがHBMの特徴です。(簡略化した図なので、TSVの数は4本しか描いていませんが、本当は1000本以上の配線が走っています。)
HBMが帯域を大きくしている方法
HBMがTSVによる接続を取ることによるメリットは、配線の長さを短縮できて、高密度に配線できることです。
(1つの配線当たりの速度)×(配線の本数)=(帯域)
となるため、配線の本数を増やせることは帯域を増やすことにダイレクトに効きます。
MicronのHBM3Gen2のデータによると、帯域が1.2TB/sでピン1本当たりの速度が9.2Gbpsなので、約1024本の配線があることがわかります。
HBMも基本的なセルの構造は、他のDRAMと同じであるため、セルの動作速度を極端に上げることはできません。そうすると、配線の本数を増やして帯域を増やす方向に動きます。
MicronのHBM3Gen2は、3GBのダイを8層積層することでトータル24GBの容量を実現しています。
このように、帯域幅を増やすためには、配線の本数を増やさないといけないです。一方で、配線の本数を増やすということは、それだけデータを受け取れるメモリの領域を増やさないといけません。
そうすると、HBMの今後の方向性は配線の本数を増やして、メモリ容量を増やしていくことになるでしょう。そうすると、必然的に積層数が増えます。
積層数が増えると問題になるのが、HBMの歩留まりです。HBMは、先ほど図で示したように、TSVでつながれた各ダイが接続されています。
配線がOpenになってしまうと使い物になりませんし(冗長性は持たせていると思いますが)、積めば積むほど接続部分の数は増えていくので不良品が出る確率は増えます。
生成AI向けGPUには、HBMが必要とされるので需要は増え続けると思われますが、歩留まりが課題になるのではないかと筆者は考えています。
積層におけるNANDとの違い
最後に、積層におけるNANDとHBMの違いを少しだけ書きます。
HBMもNANDフラッシュも、3次元的に積層している点は同じなんですが、少し毛色が違います。
HBMは、完成したDRAMダイを積層しているのに対して、NANDはシリコン基板上で三次元的にセルを積層しています。
HBMは完成品のDRAMダイを積層するので、薄片化しているとはいえ基板はそれなりの厚さがあります。NANDの三次元積層は、1つのセルの高さはnmオーダーなので、積み上げた時の高さが全然違います。
ですので、NANDは300層から400層の積層を目指して積層数競争が進められていますが、HBMの積層数がNANDと同等のレベルまで進むことはほとんど無いと思われます。(この記事を読んでいただいている方であれば、この辺は書くまでもない内容だと思いますが、念のために書いています。)
まとめ
この記事では、生成AI向けのGPUに必要とされるHBMについて解説しました。
一般向けに、HBMと生成AIを紐づけて書かれた記事を見たことがなかったので、書いてみようというコンセプトで書いています。
ざっくりした書き方になっているので、間違いや勘違い等がありましたら、教えていただけると幸いです。
記事の中でわからないところや、誤っている点がありましたらコメントかお問い合わせフォームから連絡いただけると助かります。(過去にも、読者の方からの指摘を頂いて内容を修正したことがあります。)
このブログでは、半導体に関する記事を他にも書いています。半導体メモリ業界が中心ですが、興味がある記事があれば読んでみてください。

参考文献
今回は、記事の執筆のためにたくさんの資料を参照したので、参考文献として一覧にしています。
https://pc.watch.impress.co.jp/docs/column/kaigai/646660.html
https://pc.watch.impress.co.jp/docs/column/kaigai/746633.html
https://pc.watch.impress.co.jp/docs/column/semicon/1541071.html
https://eetimes.itmedia.co.jp/ee/articles/1603/23/news033.html
https://pc.watch.impress.co.jp/docs/news/1384232.html
https://www.crucial.jp/articles/about-memory/difference-among-ddr2-ddr3-ddr4-and-ddr5-memory
https://www.rambus.com/blogs/hbm3-everything-you-need-to-know
この記事はここまでです。最後まで読んでくださってありがとうございました。

コメント
コメント一覧 (2件)
いつも勉強させていただいてます!
現在所属している部署が計測市場に注力していてHBMについて調べているところであり非常に参考になりました。
話は変わりますが、もし可能でしたらパワーMOSのプロセスや構造についての記事を書いていただけますと幸いです。
さけまる様
東急三崎口です。
コメントありがとうございます。
HBMについての記事を読んでいただき、ありがとうございます。
パワーMOSに関しては、専門ではないものでして、詳しいプロセスを存じ上げないです。
長期的には取り上げていきたいと思っておりますが、すぐに記事にできない旨ご理解いただけると幸いです。
今後ともよろしくお願いいたします。
東急三崎口